Stochastic Depth
Easy:
Imagine you’re playing a game of hide and seek with your friends. In this game, you’re the seeker, and your friends are hiding. But instead of hiding in one place, each friend decides where to hide based on a coin flip. Some might hide in the basement, some in the garden, and some might not hide at all. This randomness makes the game more interesting because you never know where your friends are hiding.
Now, think about a computer trying to learn how to recognize pictures. The computer has a big brain made up of many layers, each layer learning different things about the pictures. But instead of always using all the layers to learn, the computer sometimes decides to skip some layers based on a coin flip. This means sometimes it learns with all the layers, and sometimes it learns with only some of them.
This randomness helps the computer learn better because it’s like playing hide and seek. It makes the computer more flexible and better at recognizing pictures even if some parts of its brain (the layers) are not working at the same time. This is what we call Stochastic Depth. It’s a way to make the computer’s learning process more interesting and effective.
Another easy example:
Alright, let’s imagine you have a big, complicated maze to solve. In this maze, each layer represents a different part of the puzzle you need to figure out. Now, instead of going through every single layer of the maze every time you take a step, Stochastic Depth lets you randomly decide to skip some layers occasionally.
Imagine if, while you were solving the maze, sometimes you could jump ahead and skip a few parts of it. This skipping helps make the maze-solving process more interesting and sometimes even faster.
But don’t worry! Even if you skip some parts, you won’t get lost. There are special shortcuts that help you go from one important part of the maze to another, making sure you don’t miss anything crucial.
This skipping and using shortcuts part of Stochastic Depth helps make solving the maze more fun and efficient, just like it helps make training computers to solve complex problems more effective.

Moderate:
Stochastic Depth is a regularization technique used in deep learning, particularly in the context of training neural networks. It’s designed to improve the robustness of the model by randomly dropping out entire layers during training. This approach introduces variability into the training process, which can help the model generalize better to unseen data.
Here’s a breakdown of how Stochastic Depth works:
Layer Dropping: During training, instead of dropping out individual neurons or weights within a layer (as in dropout), Stochastic Depth randomly drops out entire layers. This means that for each training step, a different set of layers might be active, and some layers might be completely inactive.
Randomness: The layers to be dropped are chosen randomly for each training step. This randomness helps the model learn to be robust to the absence of certain layers, which can be beneficial for generalization.
Regularization Effect: By randomly dropping layers, Stochastic Depth introduces a form of regularization. This can help prevent overfitting by making the model more sensitive to the presence of all layers. It encourages the model to learn more robust features that are not dependent on any single layer.
Training Speed: While Stochastic Depth can slow down training because of the additional randomness, it can also speed up training in certain scenarios. Since some layers are dropped, the model becomes less complex for a portion of the training steps, which can lead to faster convergence.
Implementation: Stochastic Depth can be implemented in various deep learning frameworks. For example, in PyTorch, it can be implemented using the
nn.utils.stochastic_depthmodule, which provides a straightforward way to apply Stochastic Depth to a model.
In summary, Stochastic Depth is a powerful regularization technique that can improve the robustness and generalization of deep learning models by introducing randomness into the training process. It’s particularly useful in scenarios where computational resources are limited or where the model’s performance on unseen data is a priority.

Hard:
Stochastic Depth (SD) is a regularization technique used in Convolutional Neural Network (CNN) training to reduce overfitting. It works by randomly setting a fraction of the filters (or kernels) in each layer to zero during training. This reduction in complexity helps the model generalize better and improves the performance on the validation set.
SD works by calculating a stochastic weight penalty based on the average magnitude of the filters’ weights. The formula to calculate the penalty is:
Penalty = (Sigma(W²)) / (Sigma_i sigma_i(W_i)² + lambda)
In this equation:
W represents the filter weights in a single layer.
W² represents the squared magnitude of the filter weights.
sigma_i is the absolute magnitude of the W_i (i.e., the i-th filter).
lambda is a hyperparameter which controls the weight of the penalty term.
The penalty term is multiplied by a scaling factor, lambda. The scaling factor determines the relative importance of the penalty term compared to the model loss. As lambda increases, the penalty term becomes more important, and the model tries to reduce the magnitude of the filter weights.
Here’s how Stochastic Depth works:
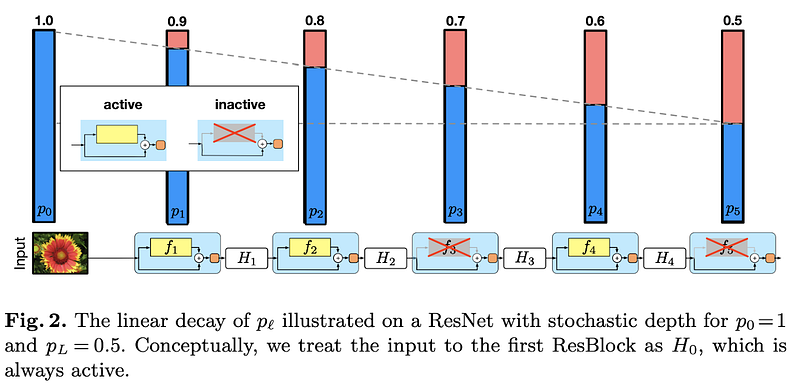
During training, instead of processing the entire network every time, SD randomly drops entire sections of the network, called residual blocks in the case of ResNets.
When a block is dropped, its contribution is bypassed, and the information simply flows through the identity connection present in these blocks.
The probability of keeping a block is defined by a survival rate. This rate controls how aggressively the network thins out during training.
This process offers a few benefits:
Ensemble Learning Effect: By training with different thinned versions of the network, SD encourages the network to learn features that are robust across these variations. This is similar to how ensemble methods combine predictions from multiple models.
Reduces Overfitting: By forcing the network to learn with dropped blocks, SD prevents it from relying too heavily on specific connections. This helps the network generalize better to unseen data.
Here are some additional points to note about Stochastic Depth:
It shares similarities with Dropout, another regularization technique that randomly drops individual neurons during training. However, SD focuses on dropping entire blocks.
The full network is used during testing to ensure optimal performance.
Stochastic Depth is a well-established method and has been shown to improve the performance of ResNets on various tasks.
A few books on deep learning that I am reading: